Naive Bayes ist ein Wahrscheinlichkeitsalgorithmus, der normalerweise für Klassifizierungsprobleme verwendet wird. Naive Bayes ist einfach, intuitiv und doch überraschend gut in vielen Fällen. Zum Beispiel sind Spam-Filter, die die E-Mail-App verwendet, auf naiven Bayes aufgebaut. In diesem Artikel werde ich die Gründe hinter Naive Bayes erklären und einen Spamfilter in Python erstellen.,y, I’ll focus on binary classification problems)

Before we get started, please memorize the notations used in this article:
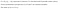
Basic Idea
To make classifications, we need to use X to predict Y., Mit anderen Worten, bei einem Datenpunkt X=(x1,x2,…,xn) ist die Ungerade von Y y. Dies kann als die folgende Gleichung umgeschrieben werden:

Dies ist die Grundidee von Naive Bayes, der Rest des Algorithmus konzentriert sich wirklich mehr darauf, wie man die bedingte Wahrscheinlichkeit oben berechnet.
Bayes-Theorem
Bisher hat Herr Bayes keinen Beitrag zum Algorithmus. Jetzt ist seine Zeit zu glänzen., Nach dem Bayes-Satz:

Dies ist eine ziemlich einfache Transformation, die jedoch die Lücke zwischen dem, was wir tun möchten, und dem, was wir tun können, überbrückt. Wir können P(Y|X) nicht direkt erhalten, aber wir können P(X|Y) und P(Y) aus den Trainingsdaten erhalten., Here’s an example:

In this case, X =(Outlook, Temperature, Humidity, Windy), and Y=Play., P(X|Y) und P(Y) können berechnet werden:

Naive Bayes Annahme und warum
Theoretisch ist es nicht schwer, P(X|Y) zu finden. In der Realität ist es jedoch viel schwieriger, da die Anzahl der Funktionen zunimmt.,


Having this amount of parameters in the model is impractical., Um dieses Problem zu lösen, wird eine naive Annahme gemacht. Wir tun so, als wären alle Funktionen unabhängig. Was bedeutet das?,div>







